Arctime提供了根据音频信号,自动切分音频,并且产生空白字幕块的功能。如果你要从头开始制作字幕(没有字幕稿)的话,那么这个功能将比较有用。
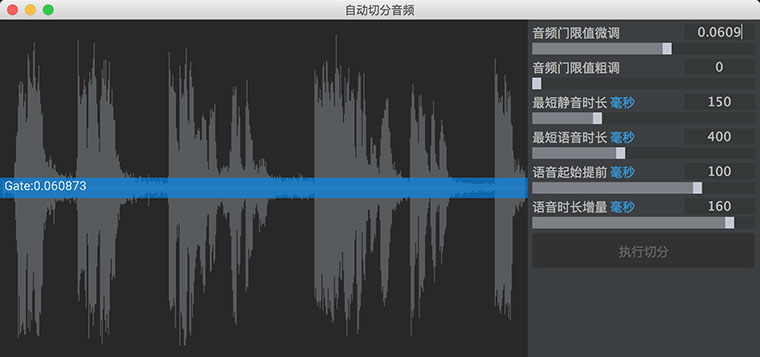
自动切分是根据门限和卷积算法工作的,首先确定一个门限值,大于该值的信号会被认为是语音信号。门限值可以用来过滤底噪、背景音乐等。然后设置下最短静音时长和最短语音时长,来确定切分的粒度。最后设置语音的提前量和延长量,给字幕前后增加呼吸空间。
用于自动切分的音频,要使用比较干净的纯人声或者只带有轻微背景音乐的音频。不适用于人声与其他声音严重混杂在一起的素材。
使用教程 >
▪ 自动切分音频(生成空白字幕块)
Arctime提供了根据音频信号,自动切分音频,并且产生空白字幕块的功能。如果你要从头开始制作字幕(没有字幕稿)的话,那么这个功能将比较有用。
自动切分是根据门限和卷积算法工作的,首先确定一个门限值,大于该值的信号会被认为是语音信号。门限值可以用来过滤底噪、背景音乐等。然后设置下最短静音时长和最短语音时长,来确定切分的粒度。最后设置语音的提前量和延长量,给字幕前后增加呼吸空间。
用于自动切分的音频,要使用比较干净的纯人声或者只带有轻微背景音乐的音频。不适用于人声与其他声音严重混杂在一起的素材。
打开方式:
主菜单►语音识别►自动切分音频(高级)
自动切分之后,会在时间轴创建一系列标记点,而不是直接创建字幕块。因为在创建标记点后,你可以调整标记点的位置,然后再从标记点创建字幕块,这样更加灵活。
请注意:
① 自动切分音频虽然方便,但效果因素材而异(仅适用于不含背景音乐的纯人声音频,或仅带有轻微背景音乐的音频,不适用于背景音乐或噪音明显的素材)。当效果不佳时,还是需要手动创建空白字幕块。
② 自动切分音频的结果仅与音频本身的特征相关,与文本区域的文稿无任何关系,所以切分结果不可用于直接填充文稿。


